
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- cloudvm
- Azure Ubuntu VM
- scratchapixel
- 에비스 맥주
- DeepLearning
- lvmdriver-1
- devstack
- 도쿄 혼자 여행
- 군입대 전 여행
- Azure Linux
- GoogleCloud
- 일본 혼자 여행
- frame stack
- c-vol.service
- OpenStack
- Azure Linux VM
- 편의점 당고
- 논문리뷰
- 에비스 맥주 기념관
- 혼자여행
- vogl
- cinder-volume
- offscreen-rendering
- 도쿄여행
- OpenGL
- 시부야 여행
- graphics programming
- OSMesa
- 학부생
- headless server
- Today
- Total
사월의눈의 DevBlog
컴공학부생이 읽어보는 논문감상 - Comicolorization : Semi-automatic manga colorization 본문
컴공학부생이 읽어보는 논문감상 - Comicolorization : Semi-automatic manga colorization
Snowapril 2019. 5. 17. 23:22Comicolorization : Semi-automatic manga colorization 논문을 읽고 리뷰아닌 감상문.
한달 전에 우연히 도쿄도서관 웹페이지에서 받은 만화가 109편있는 manga109 dataset을 받은적이 있는데
어떻게 활용해야 할지 고민하다가 클라우드에 넣은채 썩혀두고 있었는데 마침 페이스북 페이지 "Nextobe"에서
딥러닝을 이용해 만화를 자동으로 색칠해주는 모델에 대한 논문이 올라와 흥미가 생겨 한번 읽어보게 되었습니다.
그런데 읽어보니 제 데이터셋은 사용못하겠더라구요. 만화의 단색 이미지와 채색된 결과 이미지가 쌍으로 필요한데
manga109 dataset은 표지를 제외하곤 흑백이미지라 학습시키는게 불가능하다고 생각됩니다.
기존의 Colorization의 Model과 다른점은 다음 세가지입니다.
1. 학습시킬 때, reference image를 추가적으로 넣어줍니다.
2. Scene category가 아닌 Character 이름을 이용해 classification-branch를 학습시킵니다.
3. 더욱 생생한 colorization을 위해 Adversarial Loss를 이용합니다.

(그림1. Colorization results)
●주의 : 필자는 논문을 많이 읽어본 적이 없으며 전문지식 또한 그렇게 많지 않은 편인 1학년 학부생입니다. 흥미위주로 읽고 그에 대한 감상문을 쓰는 정도임을 알아주었으면 합니다
이 paper에서 제가 생각하는 핵심은
1. Color ambiguity 현상을 해결하기 위해 semi-automatic colorization method 이용.
2. Additional Input으로 별도의 reference image를 넣고 그 이미지에서 color feature를 추출하여 색칠.
3. 캐릭터 이름으로 classification 학습을 하며, CNN encoder-to-decoder network에 더욱 생생한
colorization을 위해 adversarial loss를 사용.
4.사용자가 histogram과 color-dots를 이용하여 Model과 상호적으로 결과물을 수정할 수 있도록 함.
[Explanation]
Color ambiguity현상이란 똑같은 인물, 캐릭터임에도 여러 패널에 걸쳐서 전부 다른색으로 칠해지는 현상이며
이전의 automatic method들이 잘 동작하지 않는 이유들중 하나입니다.
컴퓨터 입장에서는 똑같은 캐릭터라도 pixel value가 다르므로 각각의 패널에 있는 캐릭터가 동일한 캐릭터임을
인식하기는 쉽지 않죠. 그래서 저자가 제시한 model은 semi-automatic colorization method를 제시하였습니다.
semi-automatic colorization method란, automatic colorization method에서 별도로 reference image를 input으로 넣어주어 그 이미지에서 color feature를 추출하여 같은 캐릭터에는 그 color feature를 사용해 colorization 하게하는 method입니다.
또한 일반적인 classification branch model들은 classification을 통해 input image의 label을 인식하고 colorization할 때, label에 맞는 color feature들을 더 사용하려고 합니다. 예를들면 모델이 image를 바다로 인식했을 때, green보다는 blue를 이용하려고 하죠.
저자의 model에서는 image와 character name을 input, label으로 classification 학습을 하여 reference image의 캐릭터가 주어진 input image의 캐릭터임을 인식하는 학습을 시켜 colorization때 input image의 캐릭터를 reference image의 캐릭터임을 인식시켜 reference image의 color feature를 더 사용하게 하였습니다.
그리고 저자는 network의 objective function에 adversarial loss를 사용하였는데요. adversarial loss란, Generative Adversarial Nets - Ian Goodfellow et al. 2014논문 에서 소개된 GAN model의 손실함수인데요, GAN model에서 discriminator model이 generator model의 output이 ground-truth인지 generated-output인지 구분하려고 하며, generator model은 discriminator model이 자신의 output이 generated-output임을 구분 못하게 하기위해 더욱 더 real-distribution에 가깝게 분포를 변화시킵니다. 이 과정에서 discriminator loss와 generator loss가 서로 경쟁하는것 같다 해서 adversarial loss라고 하였습니다.
저자의 말에 따르면 recent study에서 adversarial loss가 vivid colorization에 더욱 더 도움을 준다고 하여 사용하였다고 합니다.
[Network 소개]
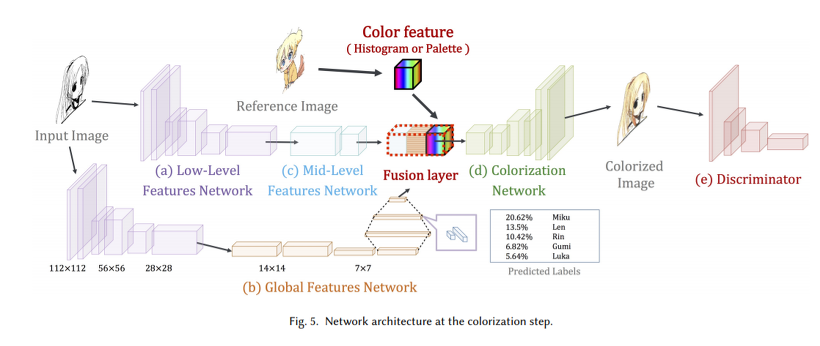
(그림2. Network Architecture)

(그림3. Network Detail)
Original 모델에서는 low-level, mid-level features CNN network에서 Input 이미지의 시각정보를 뽑아내고, global features network(CNN + FC)에서는 Input 이미지의 Scene category를 prediction하여 fusion layer에서 합쳐져 colorization을 하는데 저자가 제안한 모델도 이를 이용하지만 fusion layer에서 reference image도 함께 사용합니다.
[구현 사항]
●학습할 때, batch size는 30, iteration 550000.
●discriminator함수의 마지막 layer의 활성화 함수는 sigmoid function, 나머지 layer의 활성화 함수는 ReLU 함수.
●모든 Convolution layer 다음에는 batch-normalization layer를 삽입.
●adversarial loss와 classification loss를 이용해 L*a*b color공간에 대해 Mean-Squared-Error함수를 기준으로 학습.
●각각의 loss의 비율을 1 : 1 : 0.003을 유지.
●Optimizer는 Adam Optimizer를 이용하였으며 parameter는 α = 0.0001, β1 = 0.9, β2 = 0.999로 설정.
참고문헌.
1. Comicolorization : Semi-automatic manga colorization 논문 (그림 + 내용)
2. Generative Adversarial Nets - Ian Goodfellow et al. 2014논문
'DeepLearning > Paper Review' 카테고리의 다른 글
| 컴공학부생이 읽어보는 논문감상 - Tacotron : Toward End-To-End Speech Synthesis (2) (1) | 2017.10.25 |
|---|---|
| 컴공학부생이 읽어보는 논문감상 - Tacotron : Toward End-To-End Speech Synthesis (1) (0) | 2017.10.23 |

